Published in Articles on by Michiel van Oosterhout ~ 6 min read
This is the second article in a series of articles that aims to ultimately reproduce the custom Bash prompt in Windows Command Processor. In the previous article we started with recreating the Color extension to change the background and foreground color of output. In the next article we will recreate the Prompt extension to print colorful prompt mockups in Windows Command Processor. But before we can do that, we first need to understand Unicode in Windows Command Processor
Unicode output
Some time ago we installed and configured a special font for Console Window Host, Cascadia Mono PL. This font contains the Powerline symbols, two of which we will use as segment and sub-segment separators in our prompt. The Powerline symbols are located in the first Unicode Private Use Area starting at code point U+E0A0. To output these correctly in Windows Command Processor requires some special care.
When we emit the Unicode code point for the segment separator (U+E0B0) into a Windows Command Processor script such that it would be echo'd when the script is called, it is not guaranteed to work as expected. First we'll need to ensure a specific encoding (translation to bytes) when the script is saved, and then we need to ensure the codepage is set correctly (using the chcp command) to output those bytes
We've been using the Windows PowerShell Set-Content command to save Windows Command Processor scripts. Without the -Encoding parameter it encodes the script using the current system code page. For example, when the code page is 437 (OEM United States), U+E0B0 is encoded as 3F (question mark) because code page 437's character set does not have an entry that corresponds to U+E0B0.
When we specify -Encoding UTF8 then U+E0B0 is encoded as EE 82 B0 and a BOM is added to the start of the file.
Set-Content -NoNewline -Path "$Env:USERPROFILE\Desktop\test.cmd" -Value "@echo $([char]0xE0B0)" -Encoding UTF8
Now the result of calling this function in Windows Command Processor (call %USERPROFILE%\Desktop\test.cmd) depends on the current code page:

We can see that with code page set to 437 the 3 bytes of the BOM (EF BB BF) and the 3 bytes of the separator (EE 82 B0) are all interpreted as individual characters: ∩, ╗, ┐, and ε, é, and ░ respectively. But when we set the code page to 65001 (Unicode UTF-8) then these byte-sequences are interpreted correctly (the BOM is ignored, and EE 82 B0 is interpreted as the separator).
Solution 1: change Windows' default code page
So this means that the custom prompt would require the code page to always be set to 65001. This can be done via Windows' Settings, Time & Language, Language & Region, via Administrative language settings, via Change system locale... and checking Beta: Use Unicode UTF-8 for worldwide language support.

This can be automated using the Windows PowerShell script below.
(This script requires an elevated Windows PowerShell session, and may require a restart.)
# Ensuring the registry key exists
$path = "HKLM:\SYSTEM\CurrentControlSet\Control\Nls\CodePage"
if (-not (Test-Path -Path $path))
{
$key = New-Item -Force -ItemType Directory -Path $path
}
# Add the registry key for the font file
Write-Host "Setting default code page to 65001..." -NoNewline
$value = New-ItemProperty -Force -Name "OEMCP" -Path $path -PropertyType "String" -Value "65001"
$value = New-ItemProperty -Force -Name "MACCP" -Path $path -PropertyType "String" -Value "65001"
Write-Host " OK"
Now the result of calling our function in Windows Command Processor is immediately correct, since the code page is set to 65001 by default:

Solution 2: change code page temporarily
Usually the default code page is fine, and changing it has been known to cause problems in Windows in the past. As an alternative, we could change the code page to 65001 right before calling our function, and restore the code page immediately after. For this we can create two Commando extensions, GetCp and UseCp.
The GetCp extension
The chcp command unfortunately echos more than just the code page identifier:
Active code page: 437
The Windows PowerShell script below creates the GetCp extension, which will provide a getcp function that parses the number from chcp's output using findstr and echos only the number.
# Ensure the directory exists
$path = "$Env:LOCALAPPDATA\Commando\GetCp"
$_ = New-Item $path -Force -ItemType Directory
# Declare the ESC control code
$esc = [char]0x1B
# Declare the script contents
$script = @"
@echo off
setlocal enabledelayedexpansion
for /f "tokens=*" %%s in ('chcp') do set output=%%s
for %%w in (%output%) do (
for /f %%m in ('echo %%w ^| findstr [0-9]') do (
echo %%m
)
)
endlocal
"@
# Create the Windows Command Processor script
$path = "$path\getcp.cmd"
Set-Content -Path $path -Value $script
The script splits the output of chcp into separate words, and then matches each against the [0-9] regular expression, and outputs only the matching words. Assuming the output of chcp is similar in all Windows languages, and the only number it contains is the code page identifier, this will work.
We can call the getcp function as follows: call %CMD%\GetCp\getcp.cmd.
437
The UseCp extension
With the GetCp extension in place, we can create an extension that gets the current code page, changes the code page, executes a command, and then restores the code page.
# Ensure the directory exists
$path = "$Env:LOCALAPPDATA\Commando\UseCp"
$_ = New-Item $path -Force -ItemType Directory
# Declare the ESC control code
$esc = [char]0x1B
# Declare the script contents
$script = @"
@echo off
setlocal enabledelayedexpansion
for /f %%p in ('call %CMD%\GetCp\getcp.cmd') do set restore=chcp %%p
for /f "tokens=1,* delims= " %%b in ("%*") do set command=%%c
chcp %1 >NUL
%command%
%restore% >NUL
endlocal
"@
# Create the Windows Command Processor script
$path = "$path\usecp.cmd"
Set-Content -Path $path -Value $script
We can call the usecp function as follows: call %CMD%\UseCp\usecp.cmd 65001 call %USERPROFILE%\Desktop\test.cmd. This will call %USERPROFILE%\Desktop\test.cmd using code page 65001, which will ensure the UTF-8 encoded separator is output correctly, and afterwards restore the code page to what it was before.
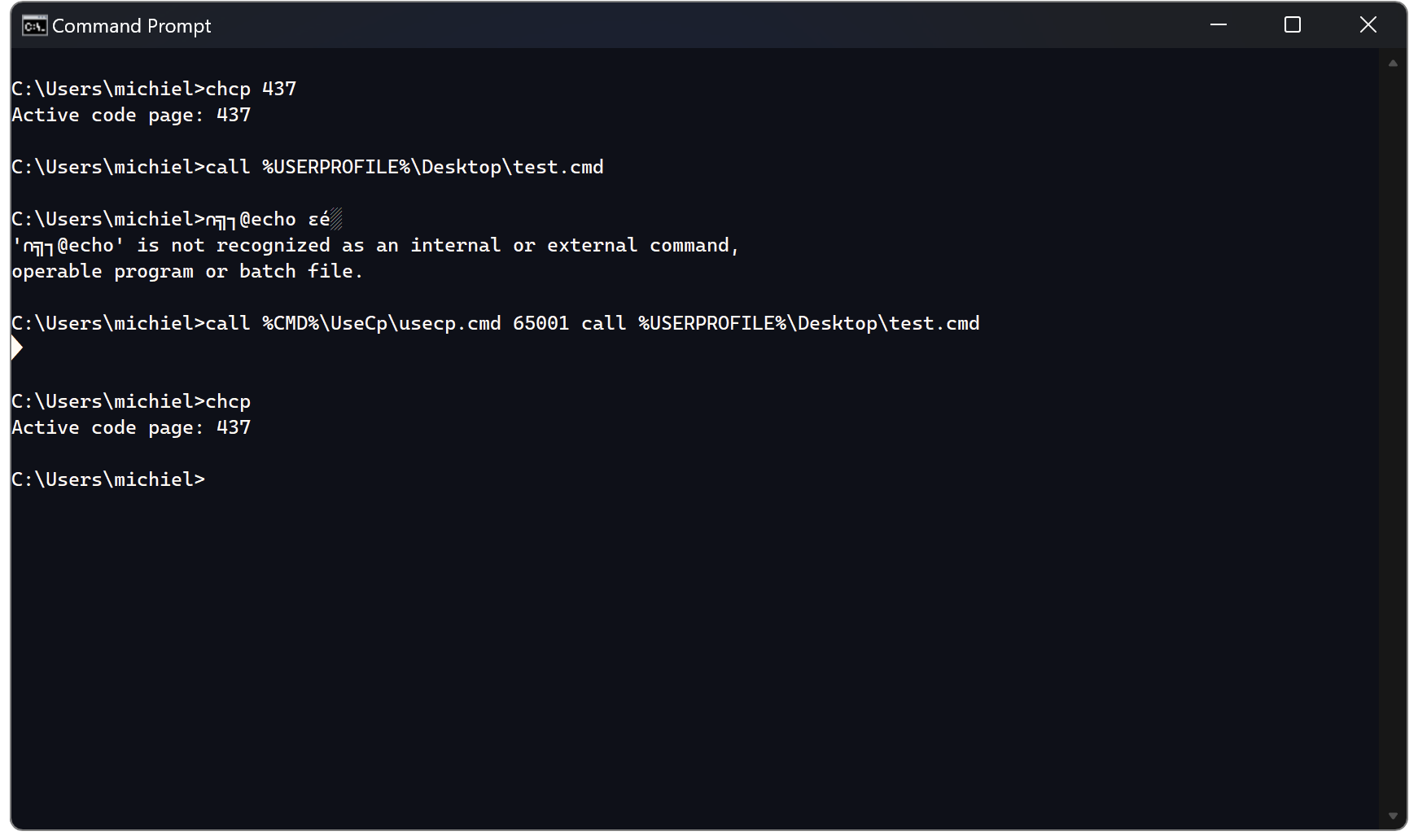
As you can see from the screenshot, the original code page is restored after the command.
Solution 3?
According to this answer on Stack Overflow, the type command checks for a UTF-16 BOM (FF FE) and will output UTF-16 encoded text correctly without requiring changes to the code page. So we could emit just U+E0B0 to a text file, using Set-Content's Unicode encoding (UTF-16 little-endian), and then use type in for /f %s in ('type %USERPROFILE%\Desktop\test.cmd') do echo %s.
But as it turns out, this actually requires changing the code page to 65001, so it is not a solution for our problem.
Conclusion
There are two ways to ensure the Powerline symbols UTF-8 in UTF-8 encoded script files are interpreted correctly by Windows Command Processor. One solution requires a system-wide change, to set Windows' default code page. The other solution requires two Commando extensions, and has a very small impact, as it limits the code page change to a single command.